STransGAN: An Empirical Study on Transformer in GANs
Abstract

Transformer becomes prevalent in computer vision, especially for high-level vision tasks. However, deploying Transformer in the generative adversarial network (GAN) framework is still an open yet challenging problem. In this paper, we conduct a comprehensive empirical study to investigate the intrinsic properties of Transformer in GAN for high-fidelity image synthesis. Our analysis highlights the importance of feature locality in image generation. We first investigate the effective ways to implement local attention. We then examine the influence of residual connections in self-attention layers and propose a novel way to reduce their negative impacts on learning discriminators and conditional generators. Our study leads to a new design of Transformers in GAN, a convolutional neural network (CNN)-free generator termed as STrans-G, which achieves competitive results in both unconditional and conditional image generations. The Transformer-based discriminator, STrans-D, also significantly reduces its gap against the CNN-based discriminators.
STrans-G
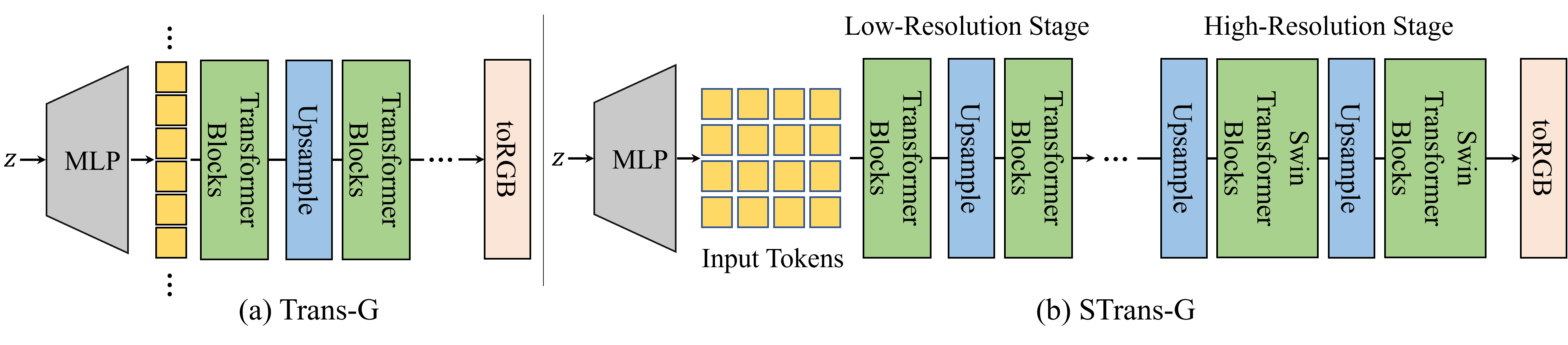
We start from a straightforward baseline structure, Trans-G, which is composed of standard vision Transformer blocks, as shown in the figure. Samples generated by Trans-G, however, often contain severe artifacts and unrealistic details, leading to poor visual quality. Through analyzing the intrinsic behavior of the attention layers, we find the global attention always breaks the locality of image data, especially when synthesizing high-resolution features. The finding motivates us to explore the effect of various local attention mechanisms in generating realistic high-resolution images. After a careful comparison of different local attention mechanisms, we finally choose Swin architecture as the building block to construct a CNN-free generator, STrans-G. The further analysis on the attention distance clearly shows the difference between the global attention and the local attention.

STrans-D
Transformer employs a residual connection around each sub-layer of self-attention and the pointwise fully connected layer. Through a detailed analysis of norm ratios, we find that residual connections tend to dominate the information flow in a Transformer-based discriminator. Consequently, sub-layers that perform self-attention and fully connected operations in the discriminator are inadvertently bypassed, causing inferior quality and slow convergence during training. We address this problem by replacing each residual connection with a skip-projection layer, which better retains the information flow in the residual blocks.
AdaNorm-T
We observe that conventional approaches of injecting conditional class information do not work well for Transformer-based conditional GAN. The main culprit lies in the large information flow through the residual connections in the Transformer generator. If the conditional information is injected within the main branch (Also known as the residual mapping path in ResNet.), it will largely be ignored and contribute little to the final outputs. We present a viable way of adopting conditional normalization layers in the trunk, which helps retain conditional information throughout the Transformer generator.
Results
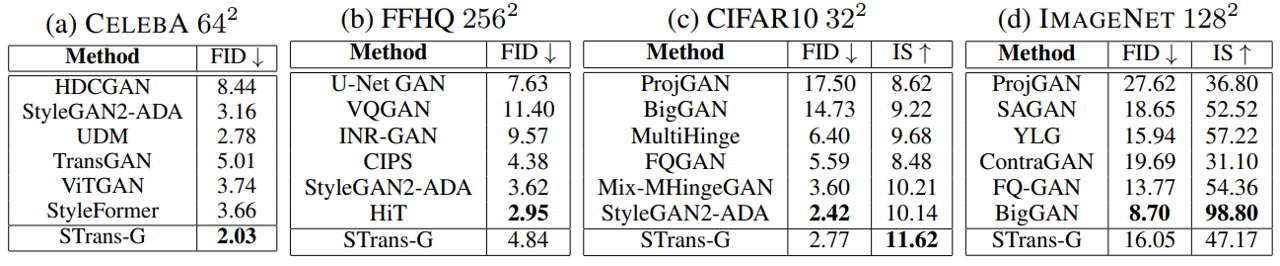
In unconditional generation, STrans-G significantly outperforms all previous methods in CelebA 64x64. It also achieves competitive performance in the high-resolution setting of FFHQ 256x256. For conditional image generation, with the proposed AdaIN-T layer, STrans-G improves the SOTA Inception Score from 10.14 to 11.62 on CIFAR10. Besides, for the first time, our study shows the potential of Transformers in the challenging ImageNet dataset.

The visual quality of these generated samples suggests the great potential of using pure Transformer blocks in GANs.
Materials


Citation
@InProceedings{xu_2021_stransgan,
author = {Xu, Rui and Xu, Xiangyu and Chen, Kai and Zhou, Bolei and Loy, Chen Change},
title = {STransGAN: An Empirical Study on Transformer in GANs},
booktitle = {arxiv},
month = {October},
year = {2021}
}
Contact
If you have any question, please contact Rui Xu at xr018@ie.cuhk.edu.hk.